Recently, self-supervised representation learning relying on vast amounts of unlabeled data has been explored as
a pre-training method for autonomous driving. However, directly applying popular contrastive or generative
methods to this problem is insufficient and may even lead to negative transfer. In this paper, we present
AD-L-JEPA, a novel self-supervised pre-training framework with a joint embedding predictive architecture (JEPA)
for automotive LiDAR object detection. Unlike existing methods, AD-L-JEPA is neither generative nor contrastive.
Instead of explicitly generating masked regions, our method predicts Bird's-Eye-View embeddings to capture the
diverse nature of driving scenes. Furthermore, our approach eliminates the need to manually form contrastive
pairs by employing explicit variance regularization to avoid representation collapse. Experimental results
demonstrate consistent improvements on the LiDAR 3D object detection downstream task across the KITTI3D, Waymo,
and ONCE datasets, while reducing GPU hours by 1.9x-2.7x and GPU memory by 2.8x-4x compared with the
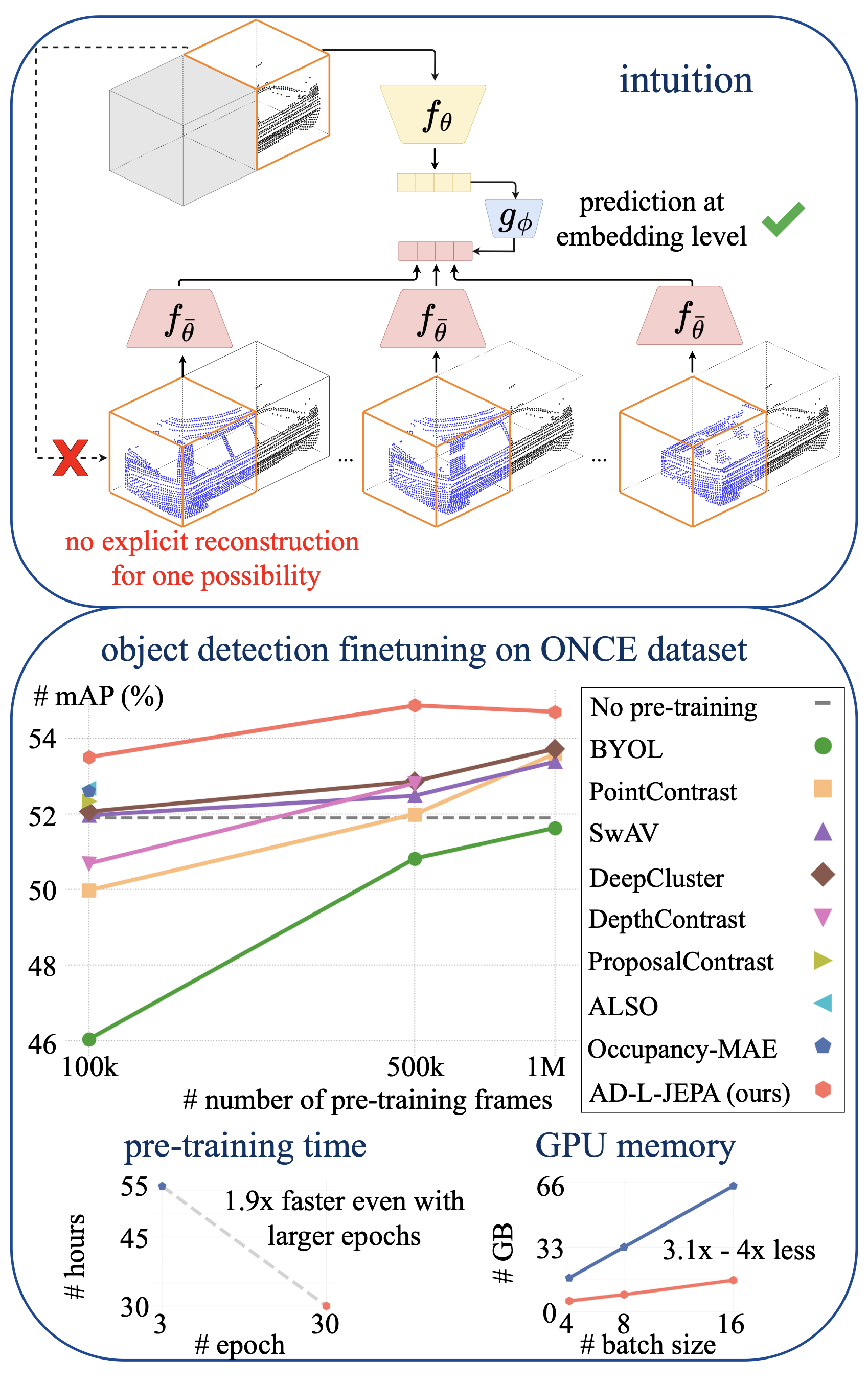
state-of-the-art method Occupancy-MAE. Notably, on the largest ONCE dataset, pre-training on 100K frames yields
a 1.61 mAP gain, better than all other methods pre-trained on either 100K or 500K frames, and pre-training on
500K frames yields a 2.98 mAP gain, better than all other methods pre-trained on either 500K or 1M frames.
AD-L-JEPA constitutes the first JEPA-based pre-training method for autonomous driving. It offers better quality,
faster, and more GPU-memory-efficient self-supervised representation learning. The source code of AD-L-JEPA is
ready to be released.
Introduction
Unlike human drivers, current autonomous driving (AD) systems still require large amounts of labeled data for
training. This supervised-only paradigm is expensive due to labeling costs and limits the scalability of these
systems. Recently, researchers have proposed self-supervised learning (SSL) across camera, LiDAR, and radar
modalities to pre-train the network without any labels and then fine-tune it with labeled data to adapt to
specific downstream tasks.
In SSL, the two most popular learning paradigms are contrastive methods and generative methods. However,
directly applying these methods for pre-training in AD is challenging and can even hurt downstream performance.
This stems from both the difficulty of defining meaningful contrastive pairs via data augmentation in driving
scenarios that contain multiple objects, and the fact that explicit scene generation is time-consuming and
insufficient to capture semantic representations of diverse driving scenarios.
In this paper, we present AD-L-JEPA (Autonomous Driving with LiDAR data via a Joint Embedding
Predictive Architecture), a novel self-supervised pre-training framework for automotive LiDAR object detection
that, as opposed to existing methods, is neither generative nor contrastive. Our method learns self-supervised
representations in Bird's Eye View (BEV) space and predicts embeddings for spatially masked regions. It omits
the need to create human-crafted positive/negative pairs, as required by contrastive learning. Furthermore,
rather than explicitly reconstructing unknown parts of the data as generative methods do, it predicts BEV
embeddings instead.
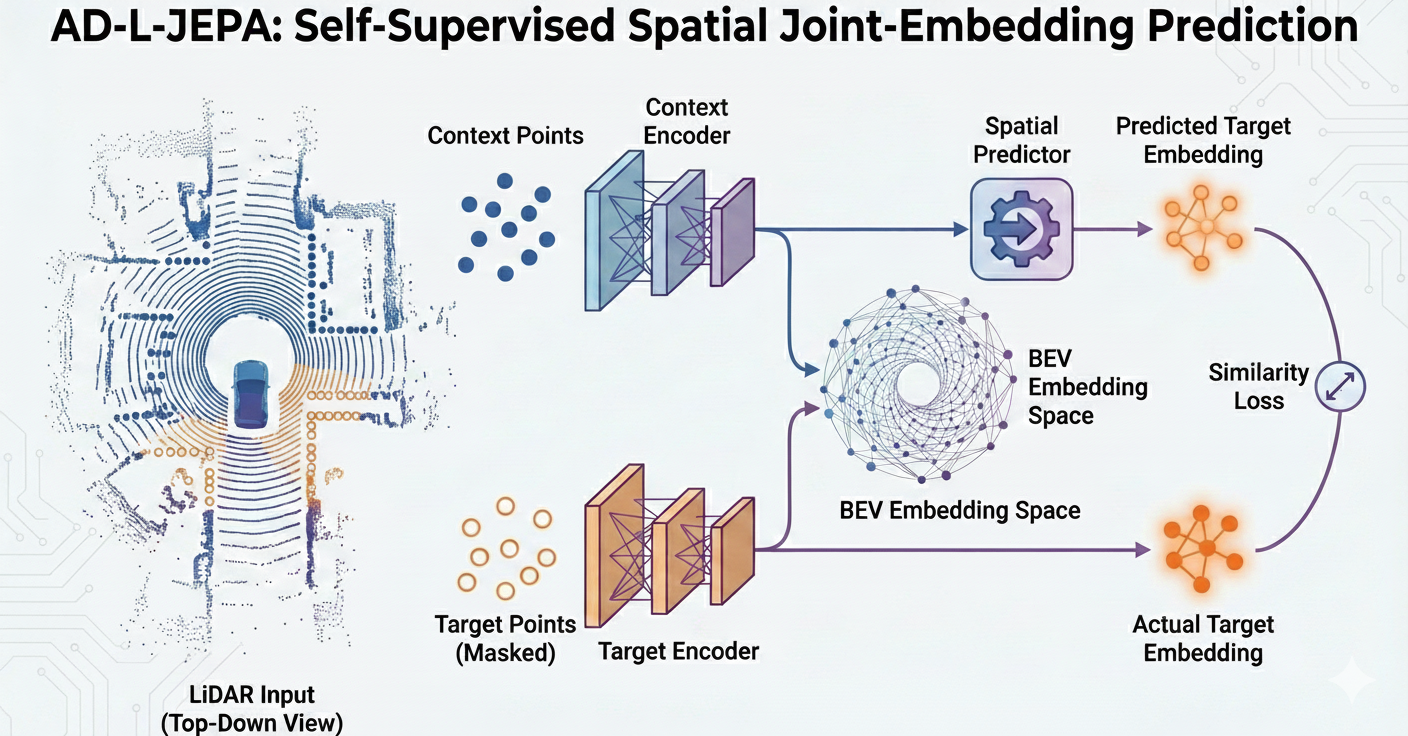
Figure 1: Intuition of AD-L-JEPA. Unlike contrastive methods that require negative
pairs or generative methods that reconstruct raw data, AD-L-JEPA predicts latent embeddings of masked regions
from visible regions in the BEV space.
Method
The architecture of AD-L-JEPA is shown in Figure 1. The overarching intuition behind our framework is as
follows: for the visible parts of the point cloud scene, the network is trained in a self-supervised manner to
predict how the invisible parts should appear in the embedding space. This enables the learning of geometrically
and semantically reasonable representations, as well as adapting to the high uncertainty nature of the AD scenes
by avoiding the explicit reconstruction of the invisible parts of the data.
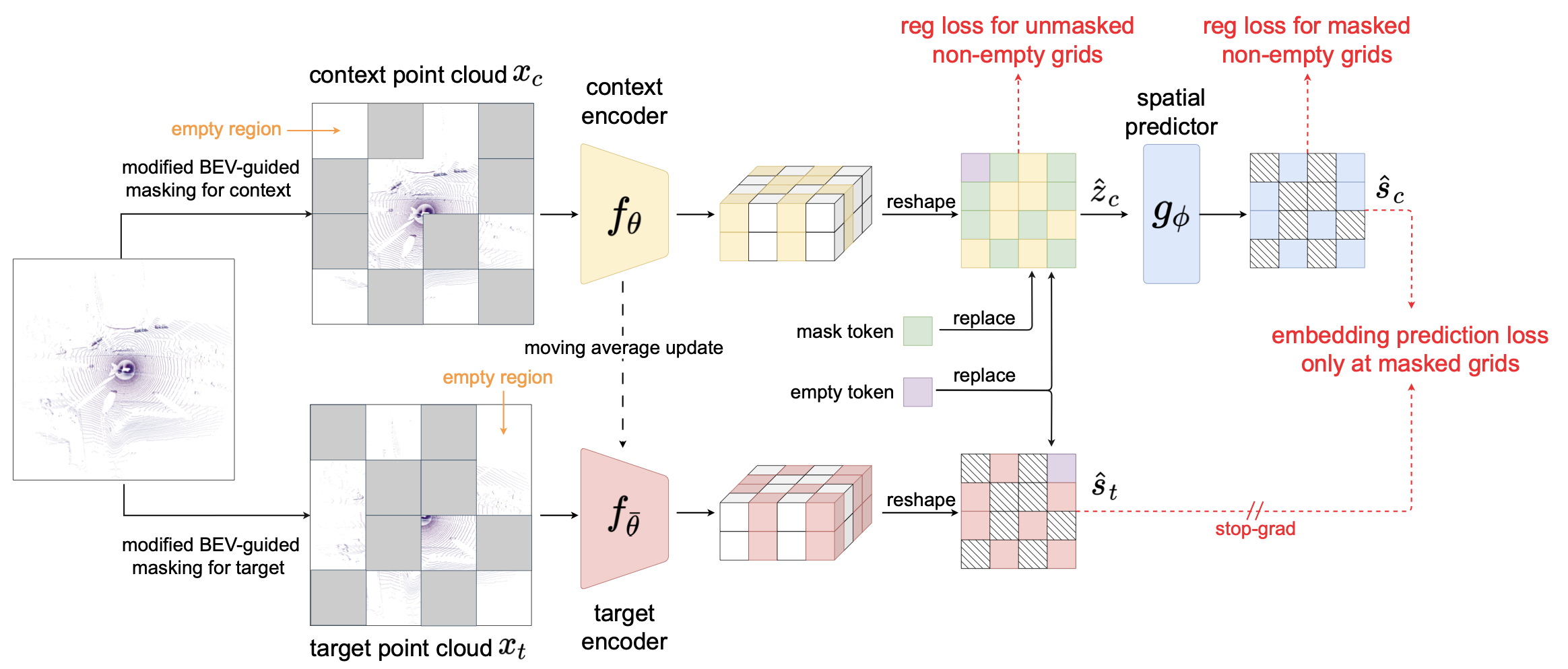
Figure 2: Overview of the AD-L-JEPA architecture: We introduce modified BEV-guided
masking to mask the input point cloud in both empty and non-empty regions. The network predicts BEV embeddings
at masked regions, leveraging variance regularization at non-empty regions following the output of the context
encoder and the lightweight spatial predictor. It also employs a moving average update of the target encoder
to learn diverse, high-level semantic representations.
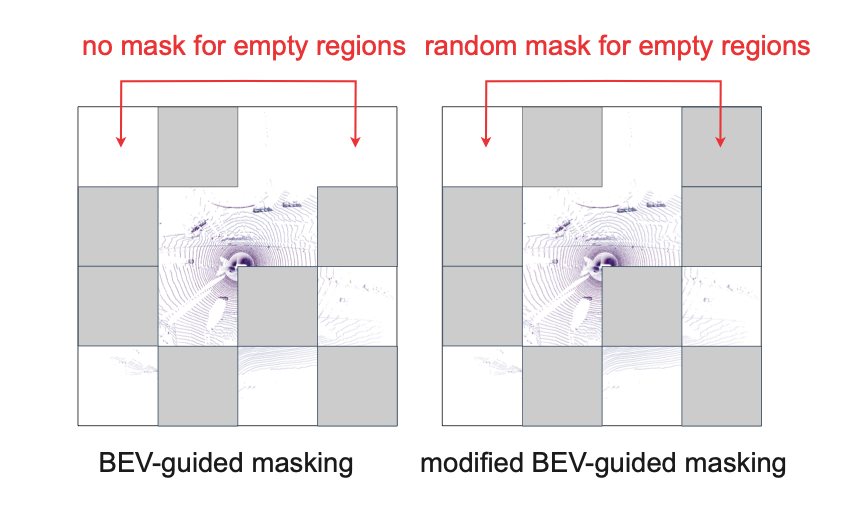
Modified BEV-Guided Masking
To learn effective representations in a self-supervised manner, masking is used to create invisible and visible
regions. The network is then trained to predict embeddings of the invisible regions based on the visible ones.
We have two design recipes for masking in AD scenarios: (1) masks are first created in the BEV embedding space
and recursively upsampled to the input point cloud to identify points to be masked; (2) both empty and non-empty
areas should be included in the visible and invisible regions created by the masks. These two criteria can be
achieved by modifying the BEV-guided masking originally proposed in [Lin et al. 2024].
Figure 3: Comparison of original BEV-guided masking with our modified version that
creates masks in both empty and non-empty regions.
Context & Target Encoders
The context encoder $f_\theta$ and target encoder $f_{\bar{\theta}}$ are backbones responsible for extracting
context embeddings from the unmasked point cloud and target embeddings from the masked point cloud,
respectively. The context encoder will later be used for fine-tuning on the downstream tasks after
self-supervised representation learning. It receives input point cloud features and outputs embeddings in a
downsampled 3D space. We obtain BEV embeddings by reshaping the 3D embeddings.
Predictor
The predictor is a lightweight, three-layer convolutional network $g_\phi$ that predicts target BEV embeddings
from visible context BEV embeddings. We denote the predicted embedding, after the $L_2$ normalization is applied
to each BEV grid's embedding dimension, as $\boldsymbol{\hat{s}}_c = g_\phi(\boldsymbol{\hat{z}}_c)$.
Training Objectives
We pre-train the network in a self-supervised manner with two losses to ensure we learn high-quality,
non-collapsed embeddings: a cosine similarity-based embedding prediction loss and a variance regularization
loss.
Embedding Prediction Loss:
$$
\mathcal{L_{\text{jepa}}} = \frac{\alpha_0}{\sum |P_n|} \sum (1 - \text{sim}(\hat{s}_c, \hat{s}_t)) +
\frac{\alpha_1}{\sum |Q_n|} \sum (1 - \text{sim}(\hat{s}_c, \hat{s}_t))
$$
where $P_n$ and $Q_n$ are subsets of masked empty and non-empty BEV grids, respectively.
Variance Regularization Loss:
$$
\mathcal{L_\text{reg}} = \beta_1 \sum v(\boldsymbol{\hat{z}}_c) + \beta_2 \sum v(\boldsymbol{\hat{s}}_c)
$$
This loss ensures that the average variance across all embedding dimensions is larger than some threshold,
preventing representation collapse.
The overall self-supervised learning loss is:
$$ \mathcal{L} = \lambda_{\text{jepa}} \mathcal{L_\text{jepa}} + \lambda_{\text{reg}} \mathcal{L_\text{reg}} $$
The parameters of the target encoder are updated through a moving average of the context encoder's parameters,
$\bar{\theta} \leftarrow \eta \bar{\theta} + (1 - \eta) \theta$, to further avoid representation collapse.
Results
We evaluate our pre-training method on three datasets of increasing scale: KITTI3D, Waymo, and ONCE. We compare
against state-of-the-art self-supervised methods like Occupancy-MAE and ALSO.
Pre-training Efficiency
Unlike Occupancy-MAE, which uses computationally expensive dense 3D convolutions to reconstruct invisible
regions, AD-L-JEPA employs a joint-embedding predictive architecture at the BEV level and omits those layers.
This results in 2.8x–3.4x lower GPU memory usage and 2.7x fewer GPU hours for
pre-training on the 20% and 100% splits of the Waymo dataset, and 3.1x–4x lower GPU memory
usage and 1.9x fewer GPU hours for pre-training on the ONCE 100k split.
Visual Comparison
We visualize the impact of pre-training label efficiency. AD-L-JEPA consistently outperforms baselines across
different label efficiencies.
Figure 4: Visual comparison of label efficiency. AD-L-JEPA demonstrates superior
performance even with limited labeled data.
Downstream Fine-tuning Performance
KITTI3D (PV-RCNN)
Method
Cars
Ped.
Cycl.
Overall
Diff.
No pre-training
84.65
56.19
72.19
71.01
-
Occupancy-MAE
84.34
57.55
71.33
71.07
+0.06
ALSO
84.64
57.09
73.72
71.82
+0.81
AD-L-JEPA (ours)
85.07
59.68
73.02
72.59
+1.58
Waymo (CenterPoint, 100% Data)
Method
Veh.
Ped.
Cycl.
Overall
Diff.
No pre-training
63.28
63.95
66.77
64.67
-
Occupancy-MAE
63.53
64.73
67.77
65.34
+0.67
AD-L-JEPA (ours)
63.58
64.58
68.07
65.41
+0.74
ONCE (SECOND)
Method
Veh.
Ped.
Cycl.
Overall
Diff.
No pre-training
71.19
26.44
58.04
51.89
-
Occupancy-MAE (100k)
73.54
25.93
58.34
52.60
+0.71
AD-L-JEPA (100k)
73.18
29.19
58.14
53.50
+1.61
AD-L-JEPA (500k)
73.25
31.91
59.47
54.87
+2.98
AD-L-JEPA (1M)
73.01
31.94
59.16
54.70
+2.81
Transfer Learning (Waymo -> KITTI)
We evaluate transfer learning by pre-training on Waymo and fine-tuning on KITTI. AD-L-JEPA consistently
outperforms baselines across different label efficiencies.
Method (100% Labels)
Cars
Ped.
Cycl.
Overall
Diff.
No pre-training
81.99
52.02
65.07
66.36
-
Occupancy-MAE
81.65
51.51
66.72
66.63
+0.27
AD-L-JEPA (ours)
80.92
52.45
69.76
67.71
+1.35
Other Evaluations
Occupancy Estimation
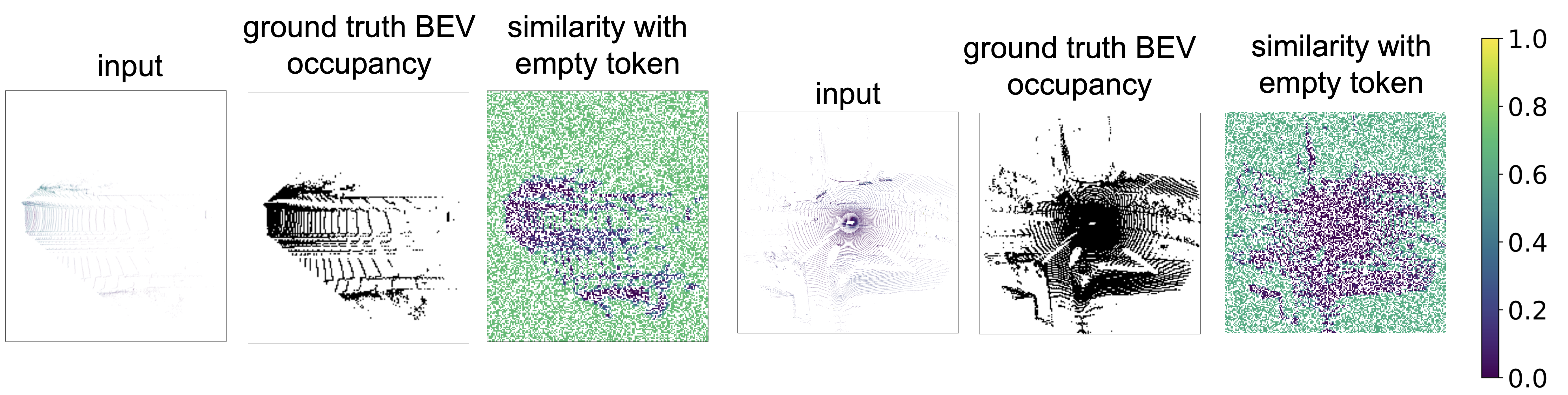
Figure 5: Masked region occupancy estimation evaluated by comparing BEV embeddings
obtained by AD-L-JEPA with the learnable empty token via the cosine similarity. Unmasked regions are ignored
and the cosine similarity in this case is represented in white color.
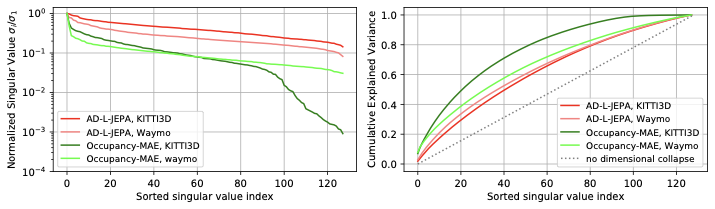
Singular Value Decomposition Analysis
Figure 6: Sorted normalized singular values and the corresponding cumulative
explained variance, obtained by singular value decomposition of pre-trained BEV embeddings. Embeddings are
obtained either with AD-L-JEPA or Occupancy-MAE.
Discussion
Saturation on Large-Scale Data: Interestingly, AD-L-JEPA pre-trained on 1M frames, although
significantly better than other methods, falls slightly behind AD-L-JEPA pre-trained on 500K frames. This small
drop aligns with existing literature showing that increasing the number of unlabeled samples consistently boosts
performance but saturates at a point. Such saturation can be explained by the data redundancy of highly similar
driving scenarios in the 1M frame setting. To validate, we took AD-L-JEPA pretrained on 100K frames and tested
it on 16K unseen LiDAR samples from the 500K/1M sets. The 500K set showed a higher average loss (0.44 vs. 0.43),
implying richer diversity and stronger fine-tuning transfer.
Future Work: For future work, we plan to extend AD-L-JEPA to leverage temporal dynamics and to
incorporate action-conditioned self-supervised representation learning in AD scenarios.
Conclusion
AD-L-JEPA constitutes the first JEPA-based pre-training method for autonomous driving. It offers better quality,
faster, and more GPU-memory-efficient self-supervised representation learning.
@misc{zhu2025selfsupervisedrepresentationlearningjoint,
title={Self-Supervised Representation Learning with Joint Embedding Predictive Architecture for
Automotive LiDAR Object Detection},
author={Haoran Zhu and Zhenyuan Dong and Kristi Topollai and Beiyao Sha and Anna Choromanska},
year={2025},
eprint={2501.04969},
archivePrefix={arXiv},
primaryClass={cs.RO}
}